
Principios SOLID – Single Responsability Principle
Los principios SOLID fueron acuñados por Robert C Martin (aka Uncle Bob), una de las leyendas de la ingeniería de software y co-creador del manifiesto Agile.
Las siglas SOLID describen 5 principios básicos para la programación orientada a objetos que sirven de base para la escritura de un código más estructurado y limpio:
- Single Responsibility Principle
- Open / Closed principle
- Liskov Substitution Principle
- Interface Segregation Principle
- Dependency Inversion Principle
Hablemos del principio Single Responsibility en esta ocasión. El principio sostiene que una clase debe tener una y sólo una responsabilidad o un único trabajo, y por tanto una sola razón para ser modificada.
Para comprender este principio, veamos esta clase:
public class User {
public int UserId {get; set;}
public string UserName {get; set;}
public string Email {get; set;}
public string AddressLine1 {get; set;}
public string AddressLine2 {get; set;}
public string City{get; set;}
public bool IsLogin(User user){get; set;}
public User UpdateAddress(User user) {}
}Podemos observar que esta clase tiene cosas relacionadas con la dirección física del usuario, pero en realidad esta clase User sólo debería encargarse de definir campos que estén relacionadas con la entidad User en si (en este caso el UserName y el Email, ya que esta es una clase base para un sistema de Log In). Por tanto, el principio de Single Responsibility no se cumple ya que esta clase tiene muchas responsabilidades (actualizar la dirección del usuario no está tan relacionada con su habilidad de ingresar al sistema)
Por tanto, para este escenario, lo mejor es que todo lo relacionado a la dirección del usuario se separe en una clase cuya única responsabilidad sea actualizar esa información, en lugar de tenerlo todo en la clase User. Crearemos pues la clase Address para mover todos los parámetros y métodos relacionados con la dirección alli:
public class User {
public int UserId {get; set;}
public string UserName {get; set;}
public string Email {get; set;}
public bool IsLogin(User user) {}
}public class Address {
public int UserId {get; set;}
public string AddressLine1 {get; set;}
public string AddressLine2 {get; set;}
public string City {get; set}
public User UpdateAddress(Address address) {}
}Podemos observar en este caso cómo las responsabilidades están correctamente repartidas entre las dos clases, y ambas cumplen el principio de Single Responsibility ya que su scope está acotado a una única entidad (User, Address). Por otro lado, si queremos modificar o adicionar campos o métodos para cada entidad, sólo lo haremos para extender la funcionalidad de esa entidad y no debe afectar el código previamente escrito.
En la siguiente ocasión hablaremos del principio Open / Closed.
LINQ and Entity Framework: Misuses and misconceptions
For any .NET Developer who works on the backend side and data processing, LINQ is one of the most important super power that .NET offers to handle data collections.
Ironically, some .NET developers hates it. The cause? It’s often a tool heavily misundesrtood. The common accusations are: “It’s slow”, “It’s over-engineering”, “It makes complicated simple things”, “Uses too much RAM”. Many of this complaints are commonly misconceptions about how to handle LINQ and what are the best practices to use it. Let’s check some of this misconceptions:
- “It’s Slow”. LINQ has a powerful concept called “materialization”. A LINQ query will delay data generation and memory usage (lazy evaluation) until we call a materialization predicate (.ToList(), FirstOrDefault(), .Single(), etc). This is often misunderstood, and when we try to chain a series of queries to process a data set in a careless way calling .ToList() before all the interactions are resolved, then premature materialize will occur, causing a lot of uneeded data will be loaded into memory. This gets worse when you have some thousands or more records to be processed, causing memory hogs and performance issues.
But if you use materialize on your benefit and avoid calling .ToList() or similar until the right time, then the performance boost for complex data processing is a real thing. On my experience, I love to work with LINQ on scenarios where a single query isn’t enough to manipulate a data set and data modeling requires some complex manipulation. On these cases, it simplifies a lot to create clean and big data sets with complex interactions, and it’s blazing fast.
Let’s take one example:var myExampleQuery = this.Find().Where(x => x.CreationDate >= someDate).ToList().Select(x => x.Name).Where(x => x.SomeField == filter).ToList();
On this simple scenario, ToList() is called just before all the filters are applied, causing an intermediate materialization of data set. A lot of records that will be filtered by the second Where will be discarded for final processing, but in the meantime, those records are already on RAM wasting resources and causing memory hogs. A right use of the LINQ syntax can be:var myExampleQuery = this.Find().Where(x => x.CreationDate >= someDate&& x => x.SomeField == filter).Select(x => x.Name).ToList();
On this case, ToList() will materialize just the required data, saving RAM and increasing performance.
Of course, I cannot ignore that having any kind of ORM between database engine and business layer will have an impact on the performance by itself, but the payload can be minimized with a proper use of the materializaton and some query optimizations, giving as result a more maintanable and robust software.
- “It’s over-engineering” – This is a common complain that comes when you try to use EF or LINQ in some scenarios where your application isn’t prepared for. When we start a new application, usually we decide how to design it. Here is where we decide what tools to use and how to integrate it. LINQ and EF are tools that requires some planification to be used correctly. Some of the benefits for using this tools are: code abstraction / substitution (for EF you can change store engine without change your code or do very minimal changes), separation of concerns (which makes sense when you expect that your application will grow organically), easyness on collection manipulation, among others.
- “It makes complicated simple things” – Sure, there is a learning curve to use LINQ and EF correctly, but it’s not too high, and it’s worth it. For people used to work with plain SQL or DAO, this involving stop thinking on specific DB / storage engine and start thinking in Entities and models. Some old-fashioned engineers (like me 🙂 ) will have some hard time to change his mindset, but with some practice you’ll start seeing the benefits of this approach.
That said, I don’t say that ALL scenarios will be a good fit with this approach. Some low-level and small tools doesn’t require this at all, and using it are simply like use a cannon to kill a bug. I’m talking here about the common business-class software scenarios where we have a big monolith application that requires flexibility and ease to maintenance. For smaller scenarios there are tools like Dapper or SqlKata which can help us to integrate some of the benefits that a ORM can bring us, but with less impact on performance.
And finally, LINQ can be used even when EF isn’t used. LINQ works independently as a meta-language to handle objects and collections, so it’s a very efficient tool to handle arrays, data collections in memory and programmatic object manipulation. In fact, it simplifies a lot many of these operations that can cause to us to write a lot of for / if / while sentences on other languages. So yes, I think that (again, in the right place) it simplifies a lot many operations. - “Uses too much RAM” – As I mentioned on the first point, this complain surges by an incorrect / careless uses of the materialize concept and writing poor LINQ sentences. LINQ manipulate objects, so it can be used either for handling Entity Framework entities or working with in-memory collections, so it’s powerful and has many benefits (which I’ve covered previously) so this implies, again, that we need to know when to use it and how to write LINQ sentences to not affect performance.
There is also things to take in mind when we use EF that can alliviate a lot the memory consumption, like switching off ObjectTrackingEnabled property when we don’t need (this property is not needed normally when we only do read-only operations, since we do not need to track changes inside an object when we edit it, so it’s better to turn it off on scenarios where we are not modifying the objects) or adjusting the concurrency settings (by default EF uses optimistic concurrency) to avoid uneeded update checks during store operations.
If you are not familiar with LINQ / EF, or you want to know more about how to improve your skills on this tools, here are some useful links that you can use to explore more:
https://www.syncfusion.com/blogs/post/8-tips-writing-best-linq-to-entities-queries.aspx
http://firstclassthoughts.co.uk/Articles/Design/LINQExtensionMethodsBestPractices.html
https://www.itprotoday.com/development-techniques-and-management/guidelines-and-best-practices-optimizing-linq-performance
Scoped vs Singleton vs Transient – ¿Cuál usar?
La inyección de dependencias en .NET Core nos permite de manera simple seguir el patrón DI y optimizar el uso de las clases y servicios que inyectamos a través de la aplicación. Una de las cosas que más hay que tomar en cuenta es el uso de recursos y de memoria que esto conlleva. Si nosotros inyectamos dependencias de manera indiscriminada copiando instancias de objetos cada que hacemos ese proceso, muy pronto empezaremos a llenar la memoria de objetos que probablemente no sean necesarios y al momento de recibir muchas peticiones corremos el riesgo de degradar el performance de nuestra aplicación.
Para optimizar el uso de la inyección de dependencias, .NET Core nos ofrece varios scopes para generar la inyección en la clase Startup.cs:
- Transient .- Cuando inyectamos una dependencia usando Transient, se generará una copia del objeto cada vez que esta dependencia sea requerida (tanto durante el request como a través de varios requests). Es el tipo de inyección más común pero también el que ocupa más memoria:
services.Addtransient<IMyInterface, Instance>(); - Scoped .- Scoped genera una única instancia del objeto durante el ciclo de vida de un request, pero generará un nuevo objeto en cada request que invoquemos:
services.AddScoped<IMyInterface, Instance>() - Singleton .- Como su nombre lo indica, Singleton generará una única instancia del objeto tanto durante el ciclo de vida de un request como para todos los requests.
services.AddSingleton<IMyInterface, Instance>()
Entonces, ¿dónde debería aplicar cada caso?. Bien, esto depende del uso que le daremos a nuestra dependencia:
- Por ejemplo, si queremos utilizar objetos donde queremos que dicha operación sea única y que sus propiedades no se compartan por otras instancias (por ejemplo, una transacción única) entonces debemos usar Transient.
- Si por ejemplo, nuestro objeto contiene propiedades que pueden compartirse durante el ciclo de vida de un request (por ejemplo, una conexión a base de datos que va a realizar varias consultas para obtener un resultado único) deberíamos utilizar Scoped
- En cambio, si nuestro objeto necesita compartir propiedades con todas las instancias y todos los ciclos de vida de los requests de nuestra aplicación (por ejemplo, un servicio que conecta a un recurso como una impresora o cualquier servicio que utilice colas de entrada / salida) deberíamos utilizar Singleton.
Espero estos ejemplos les sean de utilidad. Hasta la próxima.

En defensa de los Pull Request
Los programadores de la vieja guardia recordamos con nostalgia aquellos tiempos en los que uno simplemente cambiaba algo, lo subía a su repositorio y de ahí se iba directamente a producción… bueno, siempre que ello ocurriera sin incidentes.
Conforme los equipos crecían y cada vez se erradicaba el concepto del programador solitario, se hacía evidente que se necesitaba un mecanismo de comprobación para evitar que cuando un programador subiera algo, ese algo no rompiera el código o que introdujera algún problema de seguridad en producción. Fué entonces que el concepto de “pull request” comenzó a tomar fuerza.
Pero, ¿qué es un pull request? El concepto surge particularmente en el sistema de control de versiones git, y de hecho algunos como Mercurial han tratado de implementar algo similar. La idea central es: cuando un developer está por integrar cambios desde una rama hacia development o master, antes de que sus cambios se integren, uno o varios desarrolladores del equipo puedan revisar dichos cambios, proponer ajustes y aceptar o rechazar la integración de los mismos, esto tiene varias ventajas:
- El código que se integra es revisado por más de una persona y por tanto hay mayor confianza en que el código ha sido validado por el equipo y que no contiene errores o problemas de implementación evidentes.
- Se pueden sugerir cambios al desarrollador para mejorar el código o corregir problemas. Los comentarios sirven de evidencia de revisión y permiten una discusión abierta de la implementación, dejando lugar a menos situaciones de código oscuro o incomprensible.
- Reduce la posibilidad de introducir bugs o malas prácticas de desarrollo.
- Permite una mayor interacción entre los equipos para discutir las mejores aproximaciones a la resolución de problemas, y se obtienen consensos acerca de cómo debe implementarse una solución (no sólo tomando en cuenta la visión o experiencia del desarrollador a cargo de implementar la solución).
Al parecer, todo parece maravilloso, no?. Pues si, parece. Pero es verdad que también dentro de este proceso existen problemas que no son tan evidentes al principio pero pueden suponer más problemas que soluciones.
- El ego de las personas del equipo (en especial de los Tech Leads o Project Managers) puede derivar en convertir una buena herramienta y práctica de programación en una pesadilla proto-fascista donde sólo se plasma la visión y ego de una persona y no priva la mejora continua o las mejores prácticas.
- Si los pull requests pueden quedar atorados durante horas o días completos, hace más lento el desarrollo y provoca problemas de integración a veces difíciles de solucionar. Se necesita por tanto que los approvers sean ágiles y tengan un equilibrio entre revisar todo con cepillo de dientes y dejar que se cuelen errores evidentes por no leer el código.
- Si no hay un estándar al momento de hacer comentarios o recomendaciones puede ocurrir que dichos comentarios no sean apropiados, que se generen conflictos por malas interpretaciones o directamente una mala práctica de comunicación (insultos, sarcasmos, culpas). Se debe por tanto tener cuidado en cómo se expresan las correcciones y en qué terminos.
Recientemente un usuario en twitter comentaba lo siguiente:
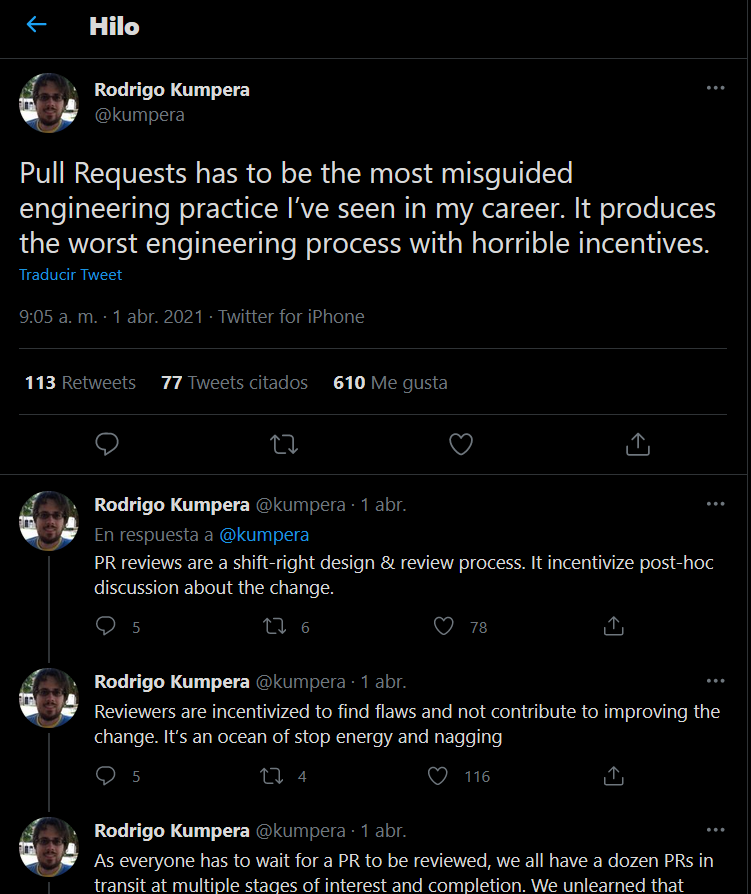
Entre otras cosas, se quejaba de precisamente todos estos problemas que se generan cuando una buena práctica de programación se implementa de manera equivocada y se producen incentivos perversos.
Mi contestación fue la siguiente:
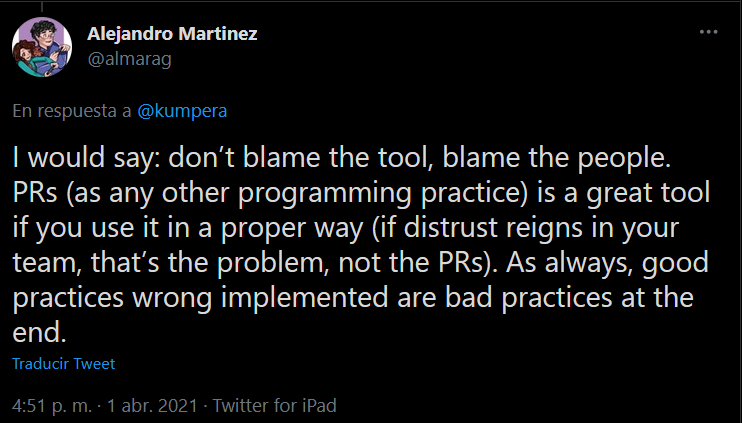
Y si. Muchas veces le echamos la culpa a las herramientas, pero en realidad el problema son las personas. Si en un equipo de desarrollo no existe confianza en el trabajo de los demás y no se asume que “shit would happen” (es decir, los errores siempre van a existir), entonces se usan estas herramientas para repartir culpas y no para corregir procesos.
Es necesario entender que el pull request debe ser “blameless” (sin culpar) y que se debe asumir que la idea es siempre mejorar a un punto en que los cambios sean lo suficientemente aceptables y no perfectos. Y que tampoco deben reflejar una visión única o autoritaria para resolver un problema.
La gran mayoría de los conflictos en los pull requests tienen que ver con:
- Malas habilidades de comunicación
- Egos inflados
- Tratar de echar la culpa fuera de nosotros
- Falta de entendimiento y de metas de equipo
Todo esto son habilidades personales, no técnicas. Los pull requests ayudan a lo técnico, pero estos puntos los debe arreglar un Project Manager y/o un Tech Lead.
Comentarios recientes